
Medical AI “scribes” are now documenting over 1.3 million physician-patient encounters each month, with investment doubling to $800 million in 2024 alone. These AI assistants promise to revolutionize healthcare delivery by reducing paperwork burdens and improving both patient care and record access; a universal win.
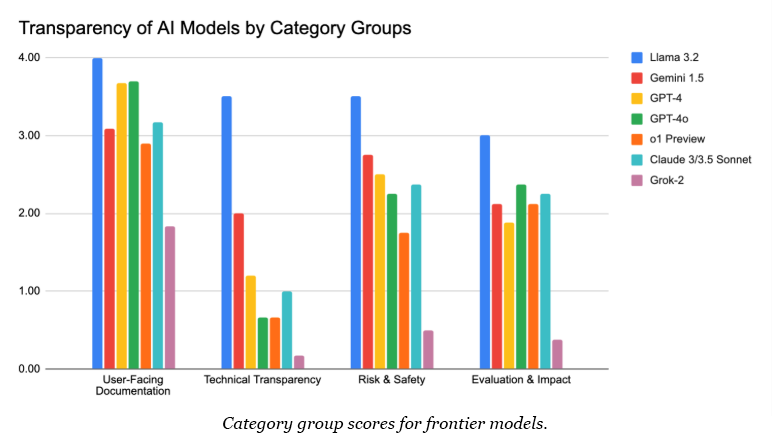
But as AI systems increasingly handle sensitive aspects of our lives, they remain significantly opaque. Our new analysis of seven leading frontier AI models across 21 metrics reveals a concerning picture: the six closed models analyzed scored between 19.4 (Grok-2) and 62.5 (Gemini 1.5) out of 100 on overall transparency, with technical details being particularly obscured.
This combination – powerful AI systems deployed in critical settings without meaningful transparency – creates a perfect storm for unaccountable failures. When something goes wrong with an AI medical assistant or an energy management system, how do you interrogate the problem and who is responsible? Without understanding these systems’ inner workings, we cannot verify their safety or interrogate their outputs.
Closed Models are Particularly Opaque About Technical Details
The problem becomes even starker when examining technical details. Even Google’s Gemini 1.5—the most transparent of the closed models—scored just 2 out of 4 on Technical Transparency metrics like model architecture and training data, while the others averaged below 1. The clearest explanation for this is that these companies view their technical details as particularly sensitive, underpinning their competitive advantage, as well as potentially exposing them to legal issues.
But this widespread technical opacity creates a dangerous precedent. While preserving companies’ ability to innovate and protecting their IP is important, the current level of secrecy makes meaningful oversight impossible. Independent researchers, journalists, and oversight bodies cannot verify capabilities, robustly test for risks, and meaningfully compare across models–fundamental requirements for responsible AI development.
Documentation Drift Makes Models Even Less Intelligible Over Time
Even when companies do share technical details, their value erodes over time due to “documentation drift”–when documentation no longer accurately reflects a system’s current state. AI companies frequently push substantial updates to their models while only sharing minimal technical details, creating an expanding gap between what’s documented and what the public interacts with.
Anthropic’s recent update to Claude 3.5 Sonnet illustrates this perfectly: the company showcased significantly improved benchmark performance but offered no details about what changes drove these improvements. This confused the developer community to the point that many have started calling it Claude 3.6 for clarity due to the dramatically improved performance. Other examples of this problem can be seen with GPT-4o, Gemini 1.5, and Grok-2. This pattern of undocumented updates means the public’s already limited understanding of these models gets worse over the course of their deployment.
Established Players are More Transparent than Startups
Our research also found a transparency divide between established tech companies and AI startups. Meta’s open-weight Llama 3.2 and Google’s Gemini 1.5 lead in transparency, scoring 88.9 and 62.5 out of 100, respectively. In contrast, the most advanced models from startups trail significantly, with OpenAI’s o1-preview scoring 44.7 and xAI’s Grok-2 managing just 19.4.

While we can’t say for sure why this is with only seven data points, one explanation is a relative lack of company resources. Google and Meta could just have more people to write documentation. Some facts suggest otherwise though. OpenAI, for example, used to release significantly more technical information when it operated as a research lab, as evidenced by GPT-2’s technical report.
One alternative explanation is that the divergence in transparency scores results from different business incentives. For AI startups whose sole revenue comes from selling model access, opacity might seem necessary to retain competitive advantage. In contrast, established tech giants with their diverse revenue streams, can afford to prioritize transparency. As Meta’s CEO Mark Zuckerberg noted, “Selling access to AI models isn’t our business model.” This creates a key challenge for transparency advocates: how do you promote openness without inadvertently punishing smaller innovators?
Current Capability Evaluations Leave Much to be Desired
The transparency problem extends even to model evaluation, where companies use common benchmarks for model capabilities, but with limitations that make meaningful comparison impossible. Each company runs its own evaluation framework with different benchmarks–often retiring metrics once they’ve been mastered–making it like comparing students’ abilities when they’ve all taken different tests. Additionally, except for Meta, no company provides enough detail about their testing methods for external verification.
Critical details about how tests were conducted – like how questions were formatted or what settings were used – are routinely omitted from documentation. This means we’re often taking companies’ at their word about their models’ capabilities. And there’s the elephant in the room that many of these benchmarks aren’t even effective at measuring what they aim to. We urgently need standardized, reproducible evaluation methods that more effectively tell us what these models can and cannot do.
Toward Increased Transparency
The transparency crisis in frontier AI requires urgent attention. Our analysis reveals four critical problems: closed models remain largely opaque about technical details, documentation is failing to keep pace with rapid updates, AI startups remain even more opaque than established players, and we still lack the ability to meaningfully compare model capabilities.

As AI systems become further embedded in critical infrastructure, from healthcare to energy grids, this opacity creates unacceptable risks. We need coordinated action from industry leaders, researchers, and policymakers to develop robust transparency standards and legislative frameworks. These standards and frameworks must balance meaningful oversight with practical business realities–protecting intellectual property while enabling accountability. Without such frameworks, we risk a future where increasingly powerful AI systems operate without effective oversight, their capabilities and limitations hidden from the public they impact.
For more information on the study, methodology, and results, see our new White Paper here.